Probabilistisches maschinelles Lernen zur Klassifizierung von Brustkrebs
Jeder, der das Buch „Thinking Fast and Slow“ von Daniel Kahnemann gelesen hat weiß, dass der Mensch selten Vorhersagen durch First Principle Thinking trifft, sondern vor allem Heuristiken und Bayes’sche Inferenz verwendet. Das Lernen bzw. der Vergleich mit dem Menschen ist immer noch die wichtigste Kenngröße für die Leistungsfähigkeit des Maschinellen Lernens. Die probabilistische Modellierung bietet dabei einen Rahmen für das Verständnis was Lernen ist und hat sich daher als einer der wichtigsten theoretischen und praktischen Ansätze für die Entwicklung des Maschinellen Lernens herausgestellt. Anhand von probabilistischer Programmierung, Bayes’scher Optimierung, Datenkompression und automatischer Modellfindung beschreiben wir in der folgenden Arbeit, wie die Unsicherheit von Modellen und Vorhersagen dargestellt und bearbeitet werden kann.

Ursprünglich wurde das Modell mit Qualitätsdaten aus der industriellen Produktion als Vorhersage der Produktqualität bzw. des Produktes entwickelt. Dieser Datensatz konnte natürlich im Paper nicht öffentlich genutzt werden. Um so interessanter ist nun, dass wir anhand eines öffentlichen Datensatzes als Beispiel ein probabilistisches neuronales Netz zur Vorhersage der Bösartigkeit von Brustkrebszellen implementiert haben, dessen Merkmale zur Formulierung und zum Training eines Modells für ein binäres Klassifikationsproblem verwendet werden.
Wir, das sind Dr. rer. Nat. Anastasia-Maria Leventi-Peetz (KI-Expertin beim BSI) und Dipl. Phys. Kai Weber. Und nun viel Spaß beim Lesen.
Link zum Paper: https://doi.org/10.3934/mbe.2023029
Abstrakt
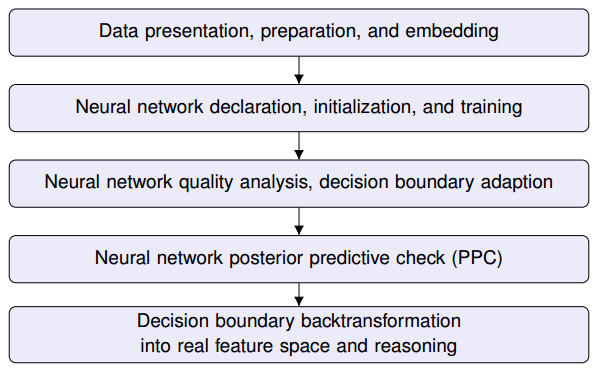
A probabilistic neural network has been implemented to predict the malignancy of breast cancer cells, based on a data set, the features of which are used for the formulation and training of a model for a binary classification problem. The focus is placed on considerations when building the model, in order to achieve not only accuracy but also a safe quantification of the expected uncertainty of the calculated network parameters and the medical prognosis. The source code is included to make the results reproducible, also in accordance with the latest trending in machine learning research, named Papers with Code. The various steps taken for the code development are introduced in detail but also the results are visually displayed and critically analyzed also in the sense of explainable artificial intelligence. In statistical-classification problems, the decision boundary is the region of the problem space in which the classification label of the classifier is ambiguous. Problem aspects and model parameters which influence the decision boundary are a special aspect of practical investigation considered in this work. Classification results issued by technically transparent machine learning software can inspire more confidence, as regards their trustworthiness which is very important, especially in the case of medical prognosis. Furthermore, transparency allows the user to adapt models and learning processes to the specific needs of a problem and has a boosting influence on the development of new methods in relevant machine learning fields (transfer learning).
Keywords:





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}