Probabilistic machine learning for breast cancer classification
Anyone who has read the book “Thinking Fast and Slow” by Daniel Kahnemann knows that humans rarely make predictions by first principle thinking, but use mainly heuristics and Bayesian inference. Learning or comparison with humans is still the most important metric for machine learning performance. In this context, probabilistic modeling provides a framework for understanding what learning is and has therefore emerged as one of the most important theoretical and practical approaches for the development of machine learning. Using probabilistic programming, Bayesian optimization, data compression, and automatic model discovery, we describe in the following work how uncertainty in models and predictions can be represented and handled.

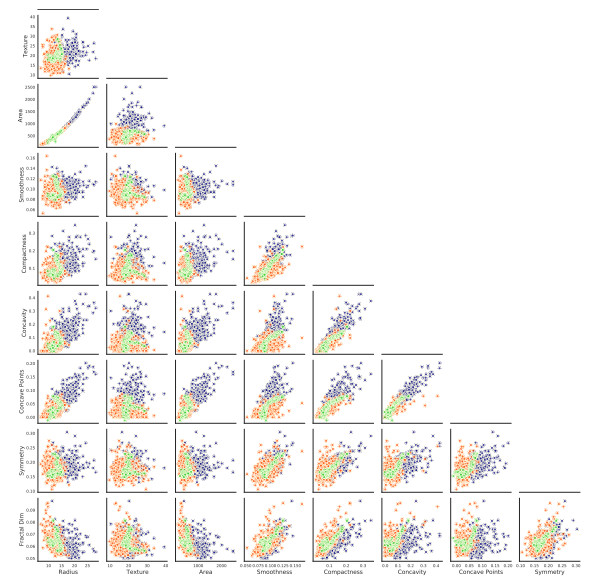
Originally, the model was developed using quality data from industrial production as a prediction of product quality or product. Of course, this data set could not be used openly in the paper. It is now all the more interesting that, using a public dataset as an example, we have implemented a probabilistic neural network for predicting the malignancy of breast cancer cells, whose features are used to formulate and train a model for a binary classification problem.
We, that is Dr. rer. Nat. Anastasia-Maria Leventi-Peetz (AI expert at BSI) and Dipl. Phys. Kai Weber. And now have fun reading.
Link to the Paper: https://doi.org/10.3934/mbe.2023029
Abstract
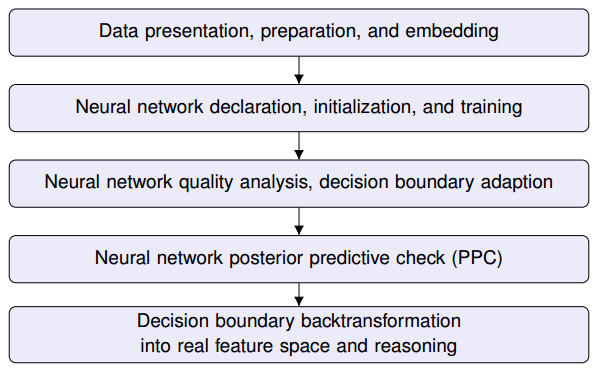
A probabilistic neural network has been implemented to predict the malignancy of breast cancer cells, based on a data set, the features of which are used for the formulation and training of a model for a binary classification problem. The focus is placed on considerations when building the model, in order to achieve not only accuracy but also a safe quantification of the expected uncertainty of the calculated network parameters and the medical prognosis. The source code is included to make the results reproducible, also in accordance with the latest trending in machine learning research, named Papers with Code. The various steps taken for the code development are introduced in detail but also the results are visually displayed and critically analyzed also in the sense of explainable artificial intelligence. In statistical-classification problems, the decision boundary is the region of the problem space in which the classification label of the classifier is ambiguous. Problem aspects and model parameters which influence the decision boundary are a special aspect of practical investigation considered in this work. Classification results issued by technically transparent machine learning software can inspire more confidence, as regards their trustworthiness which is very important, especially in the case of medical prognosis. Furthermore, transparency allows the user to adapt models and learning processes to the specific needs of a problem and has a boosting influence on the development of new methods in relevant machine learning fields (transfer learning).
Keywords:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}